Guiding Principles
Core Philosophy: “Build Up, Don’t Pile On”
- Separation of Concerns: Each model should have a distinct and clear purpose.
- Progressive Enrichment: Introduce complexity incrementally, adding layers as needed.
- Domain-Driven Design: Organise related logic into cohesive groups.
- Reusability First: Prioritise designs that accommodate multiple use cases.
- Test at Every Layer: Validate functionality continuously, rather than waiting until the end.
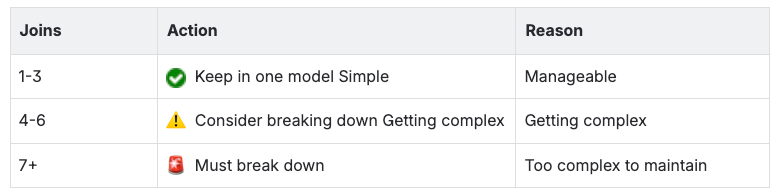
When to Break Down Models
How to Break Down Complex Models
A common challenge in data engineering is managing complex SQL models with numerous joins and transformations. A single, monolithic model can become a maintenance nightmare, making debugging and updates difficult. The solution is to break down the model into a series of intermediate models.
This layered approach offers several benefits:
- Clear Data Lineage: Each model builds logically on the previous one.
- Simplified Debugging: If an issue arises, you can isolate it to a specific layer.
- Incremental Development: You can build and test each layer independently.
- Reusability: A foundational model can be reused by multiple downstream models.
Below is a generic refactoring of a complex SQL model, demonstrating how to break it down into a logical sequence of intermediate models.
1. The Foundation Layer: intermediate_core.sql
This first model establishes the base of your data model. It should include the most critical tables and columns, forming a central “core” dataset that subsequent models will build upon. The goal is to perform only the essential joins and select the foundational data points.
-- This model forms the foundational dataset by selecting core fields
-- from primary staging tables.
{{ config(materialized = 'table') }}
with
-- Select from the main subject table
base_subject as (
select * from {{ ref('stg_main_subject_table') }}
),
-- Join with a key related table
related_table_a as (
select * from {{ ref('stg_related_table_a') }}
),
-- Join with another essential table
related_table_b as (
select * from {{ ref('stg_related_table_b') }}
)
select
-- Core fields from the main table
base_subject.primary_key,
base_subject.core_field_1,
base_subject.core_field_2,
-- Joining key fields
related_table_a.lookup_key_a,
related_table_b.lookup_key_b,
-- Create a surrogate key for the entity
{{ dbt_utils.generate_surrogate_key(['base_subject.primary_key']) }} as entity_surrogate_key
from base_subject
left join related_table_a
on base_subject.common_id = related_table_a.common_id
inner join related_table_b
on base_subject.another_id = related_table_b.another_id
2. The Enrichment Layer: intermediate_enrichment.sql
This model takes the core dataset from the previous layer and enriches it with additional information from other sources. This is where you would typically join in more granular data or supplementary attributes.
-- This model enriches the core dataset with additional attributes
-- from other staging tables.
{{ config(materialized = 'table') }}
with
-- Reference the core model from the previous step
core_data as (
select * from {{ ref('intermediate_core') }}
),
-- Select from a table with supplemental data
supplementary_data as (
select * from {{ ref('stg_supplementary_data') }}
),
-- Select from a table with dimension data
dimension_data as (
select * from {{ ref('stg_dimension_data') }}
)
select
-- Select all columns from the previous model
core_data.*,
-- Add new, enriched fields
supplementary_data.extra_attribute,
supplementary_data.derived_field,
dimension_data.dimension_value
from core_data
left join supplementary_data
on core_data.primary_key = supplementary_data.primary_key
left join dimension_data
on core_data.lookup_key_a = dimension_data.lookup_key_a
3. The Final Transformation Layer: final_model.sql
This final model brings everything together. It’s where you apply the last set of business logic, such as CASE statements, data type casting, and final column selection. This layer also handles data lineage and slowly changing dimension (SCD) logic to prepare the data for consumption.
-- This is the final model, where all transformations are complete.
-- It selects and casts the final set of columns for end-user consumption.
{{ config(materialized = 'table') }}
with
-- Reference the enriched data from the previous layer
enriched_records as (
select * from {{ ref('intermediate_enrichment') }}
),
final_transformations as (
select
-- Casting key IDs to appropriate types
primary_key::varchar(50) as final_entity_id,
entity_surrogate_key,
-- Applying business logic with a CASE statement
case
when primary_key like 'ABC%' then 'Type A'
else 'Type B'
end as entity_type,
-- Final column selection and aliasing
core_field_1 as final_attribute_1,
derived_field as final_attribute_2,
extra_attribute as final_attribute_3,
-- Example of SCD Type 2 logic
effective_start_date as eff_start_dttm,
case
when is_deleted_flag then current_timestamp
else '9999-12-31 23:59:59'::timestamp
end as eff_end_dttm
from enriched_records
)
-- Final SELECT statement to materialize the model
select * from final_transformations
This article was originally published at https://medium.com/@aradsouza/how-to-refactor-a-complex-logic-in-dbt-models-ffba35f45e62