In this article, I use a cooking analogy to explain the different layers of dbt modeling. If you haven’t yet read my article on dbt modeling layers, I encourage you to check it out for additional context here
To make the concept of dbt modeling layers more relatable, let’s walk through a familiar scenario — preparing a meal. Specifically, let’s say you are making fried rice. Each step in the cooking process mirrors a layer in dbt, and together, they form a well-orchestrated data pipeline.
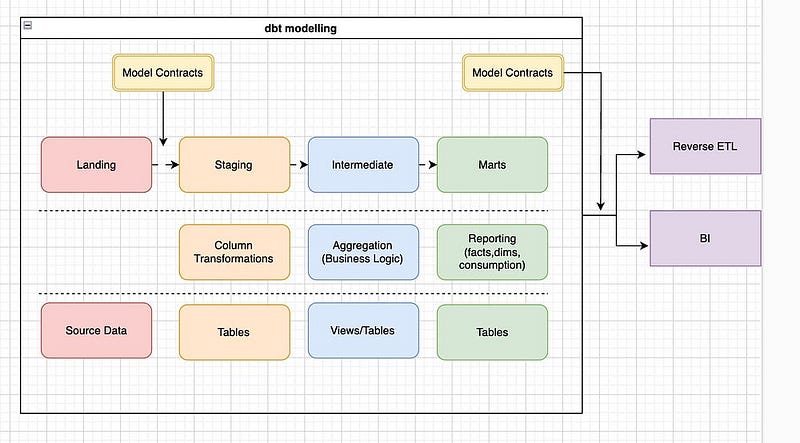
Staging layer — Prepping Ingredients
dbt — This layer pulls raw data from source system and applies light transformations such as renaming columns, casting data types, and filtering out bad records.
cooking — Think of this as washing the rice, chopping vegetables, and marinating the meat. You are not cooking yet — just making sure everything is clean and ready.
If you skip cleaning your ingredients or fail to discard spoiled items before cooking, you’re likely to end up with food poisoning. The same principle applies to data products — if you don’t properly clean and validate your raw data, the outcomes can be unreliable or even harmful to your business decisions.
Intermediate Layer — Cooking the Ingredients
dbt — This layer combines and transforms the staged data into more meaningful datasets. It often includes joins, aggregations, and business logic.
cooking — Now you are stir-frying the ingredients — mixing rice, veggies, and sauces together. This is where the actual cooking happens.
Matrts Layer — Serving the Dish
dbt — These are the final models used by business users or dashboards. They are clean, well-documented, and ready for consumption.
cooking — You plate the fried rice, garnish it, and serve it to your guests. It’s presentation ready.
Now Imagine you are running a restaurant.
Every day, you receive fresh deliveries of raw ingredients — vegetables, meats, spices, etc. These are your daily deltas — the new data.
Now, you wouldn’t rewash all the ingredients you have already cleaned and stored from previous days, right — [aka full refresh]? That would waste time and resources. Instead, you only wash and prep the new ingredients that arrived today and then send them through your kitchen’s production line to be cooked and served.
In the same way, in a data pipeline using dbt, you don’t reprocess all the data every day. You only process the new or changed data (delta) and push it through your transformation layers — staging, intermediate, and marts — just like your kitchen workflow.
You don’t want to keep reprocessing everything from scratch every day. Just like in the restaurant, you only handle the new ingredients — the deltas — and move them through your kitchen (aka your data pipeline).
Hopefully, I have given you all a laugh — but more importantly, I hope it’s clear now why we need all those layers in dbt. Each one has a purpose, just like every station in a well-run kitchen.
This article was originally published at https://medium.com/@aradsouza/dbt-as-well-run-kitchen-station-14f03adaa1b4