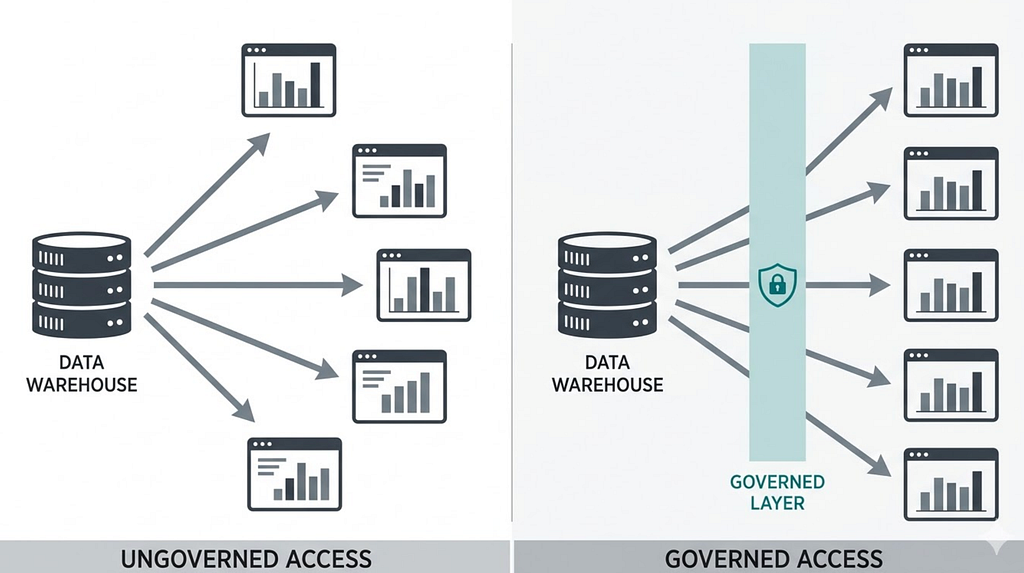
The Problem: Metric Disagreement Across Tools and Teams
Most data teams have encountered this situation: two reports that should show the same number don’t. Finance reports one revenue figure. Marketing reports another. An analyst pulls a third from the warehouse directly. The definitions look similar, but the filters, time grains, or inclusion criteria differ just enough to produce different results.
This is a common and well-documented problem in enterprise data. It’s not caused by bad data or incompetent teams — it’s caused by an architectural gap. In most modern data stacks, there is no single, governed layer where business metrics are defined and enforced. Instead, metric definitions are scattered across BI tools, spreadsheets, SQL scripts, and ad-hoc notebooks, each maintained independently with no mechanism for consistency.
The practical consequences are significant. Stakeholders spend time reconciling numbers rather than acting on them. Data teams get pulled into validation work that crowds out higher-value analysis. And trust in data erodes — once a number is wrong in a high-visibility context, rebuilding confidence takes considerably longer than fixing the definition.
Where Metric Definitions Actually Live
In most organisations, business logic is embedded in several places simultaneously:
- BI tool calculated fields — metric definitions inside Tableau, Power BI, Looker, or similar platforms, scoped to that tool only
- Spreadsheets — Excel or Google Sheets workbooks with formulas that encode business rules, often undocumented and unversioned
- Ad-hoc SQL — queries saved locally by analysts, sometimes shared via Slack or email, rarely maintained after initial use
- LookML/PowerBI/Tableau/semantic definitions within BI platforms — governed within a single tool but not portable to other consumers
- dbt model logic — business rules embedded in SQL transformations, but not formalised as reusable metric definitions
Each of these represents a reasonable attempt to capture business logic. The problem isn’t any individual approach — it’s the duplication. When the same metric is independently defined in five places, there are five opportunities for drift. And drift is the default state; consistency requires active governance that most stacks don’t provide.
This pattern – critical business logic existing outside any formal governance framework – is sometimes called 'Shadow BI'. It’s not a failure of discipline. It’s a predictable outcome of architectures that don’t provide a dedicated layer for metric governance.
Why the BI Layer Is the Wrong Place for Metric Governance
The most common location for metric definitions is the BI layer — the tools with which business users consume data. This is intuitive: that’s where metrics are used, so that’s where they get defined.
But the BI layer has structural limitations that make it unsuitable as the system of record for business metrics.
Tool specificity. A metric defined in Tableau doesn’t exist in Power BI, in a Python notebook, or in an API endpoint. If your organisation uses multiple consumption tools — or if non-BI consumers need access to the same metric — you’re maintaining parallel definitions with no synchronisation mechanism.
Limited version control. Most BI tools don’t provide Git-style version history, peer review workflows, or rollback capabilities for metric definitions. A definition change is typically a UI action with no formal review process. In contrast, a metric defined as 'code' in a dbt project goes through a pull request, is reviewed by peers, and has a full audit trail.
No extensibility to non-BI consumers. When an AI agent, a machine learning pipeline, a reverse ETL process, or an embedded analytics product needs a metric, it can’t query the BI tool’s internal semantic model. The definition must be re-implemented — introducing another copy, another opportunity for drift.
The Analyst Bottleneck
Without a governed metric layer, the person who “knows the data” becomes the de facto source of truth. They are the ones who know that “active users” means “distinct users who logged in within 30 days, excluding internal accounts and test users, at a monthly grain.”
This creates a well-known bottleneck pattern. Self-serve analytics doesn’t function in practice because every answer requires validation by someone with institutional knowledge. That person’s capacity for strategic analytical work — the work they were hired for — decreases as the organisation’s data footprint grows.
This is a scaling problem. It gets worse, not better, as more teams, tools, and consumers enter the picture.
The Compounding Effect
Every new consumer of data — a new dashboard, a new analytics platform, a new AI-powered feature — inherits the current state of metric inconsistency. Each new consumer is another place where business logic gets independently defined.
This compounding is why metric drift accelerates over time. Organisations don’t converge towards consistency by default; they diverge. The cost of remediation increases with each new silo, which is why addressing the architectural gap early yields disproportionate long-term value.
The Architectural Fix: A Semantic Layer in the Transformation Layer
The solution is conceptually straightforward: move metric definitions out of the BI layer and into the transformation layer — the governed, version-controlled, tested layer where data models already live.
This is what a semantic layer provides. It’s an intermediary between your data models and your consumption tools. Instead of each tool defining metrics independently, every consumer — dashboards, notebooks, AI agents, and APIs — queries metrics through a single governed layer.
Without a semantic layer:
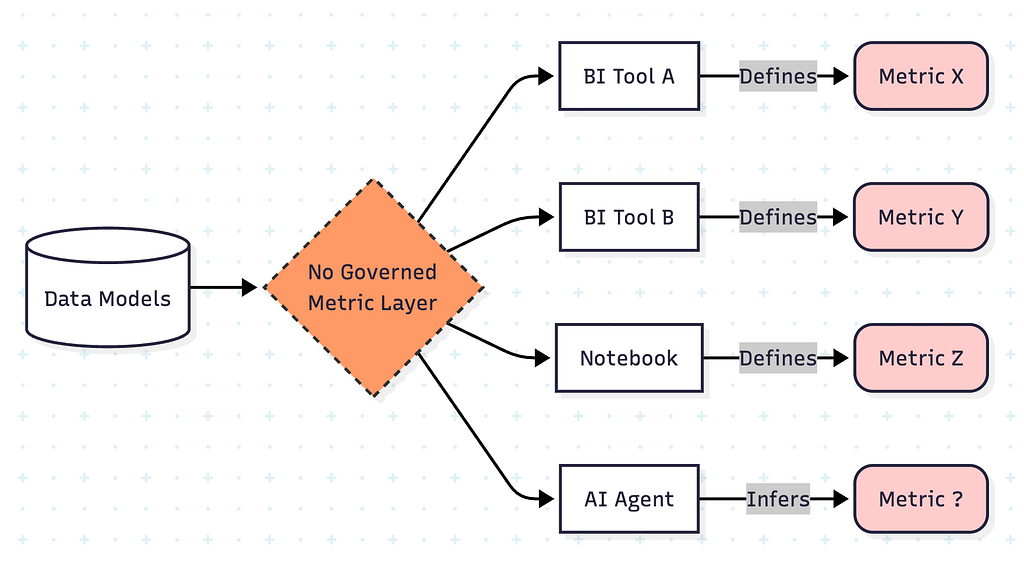
without governed semantic layer, metrics are scattered — no single source of truth
With a semantic layer:
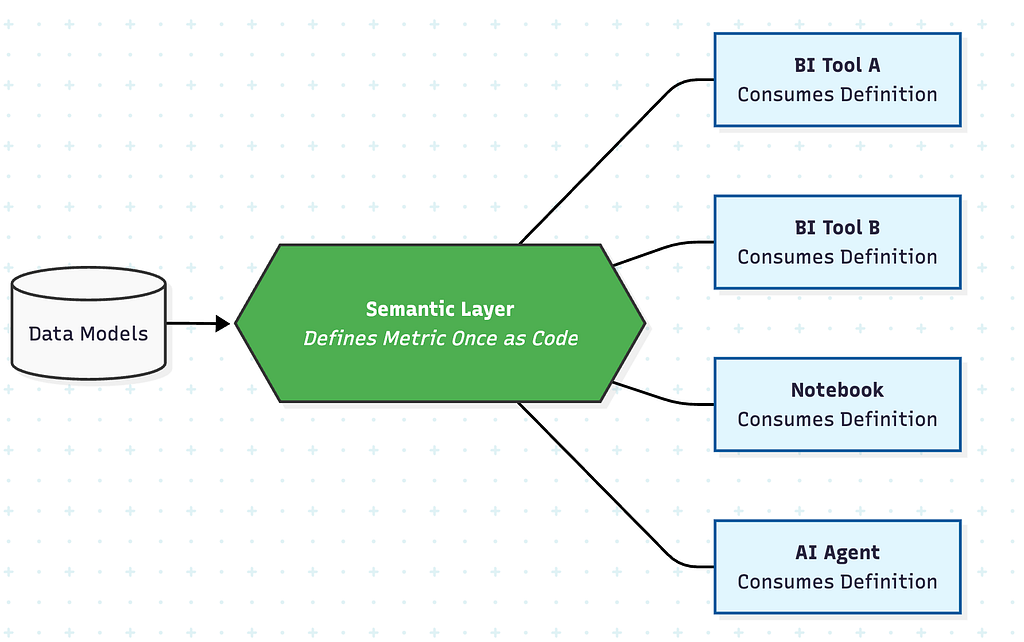
The semantic layer doesn’t replace existing tools or require warehouse restructuring. It adds a governed definition layer that every downstream consumer inherits.
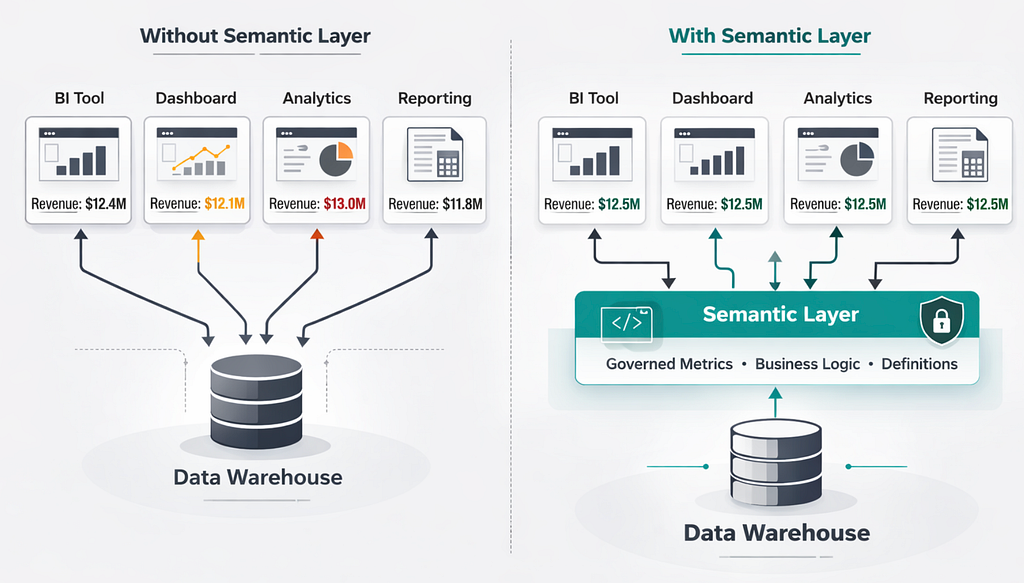
Metrics as Code
The modern approach to semantic layers — particularly the dbt Semantic Layer powered by MetricFlow — treats metric definitions as code. Definitions are written in YAML files that live alongside dbt models in a Git repository. They go through pull requests, are tested in CI/CD, and carry clear ownership.
This applies the same governance model that software engineering has used for decades — version control, peer review, automated testing, and audit trails — to business logic. It’s a well-understood pattern; the only new aspect is applying it to metric definitions rather than application code.
MetricFlow, the engine that powers the dbt Semantic Layer, is now open source under the Apache 2.0 licence and is part of the Open Semantic Interchange (OSI) initiative — a cross-vendor effort toward portable semantic standards involving dbt Labs, Snowflake, Salesforce, Atlan, Alation, and others.
The Compounding Value of Governed Data Definitions
The metric consistency problem is ultimately a governance gap. The data exists. The tools exist. What’s missing is an architectural layer that ensures every consumer — every tool, every team, every automated system — works from the same definitions.
Building that layer is an investment that compounds. Every new dashboard, every new AI workload, every new data consumer inherits the governance you’ve built. The alternative — allowing metric definitions to drift across ungoverned silos — also compounds, but in the wrong direction.
The tools and standards for governed semantic layers have matured significantly over the past two years, with MetricFlow’s open-sourcing and the OSI initiative signalling broader industry convergence. For data teams evaluating where to invest, this is a foundation worth building early.
Found this useful? Follow me on Medium (aradsouza) or LinkedIn https://www.linkedin.com/in/alwynanildsouza/
for more practitioner-voice content on dbt, data mesh, and the modern data stack.
Why Data Teams Need a Semantic Layer was originally published in Towards Data Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
This article was originally published at https://medium.com/towards-data-engineering/why-data-teams-need-a-semantic-layer-83947a5a0057?source=rss-670f6306e3c0------2