What DevOps taught us about preventing problems instead of reacting to them
The DevOps Parallel
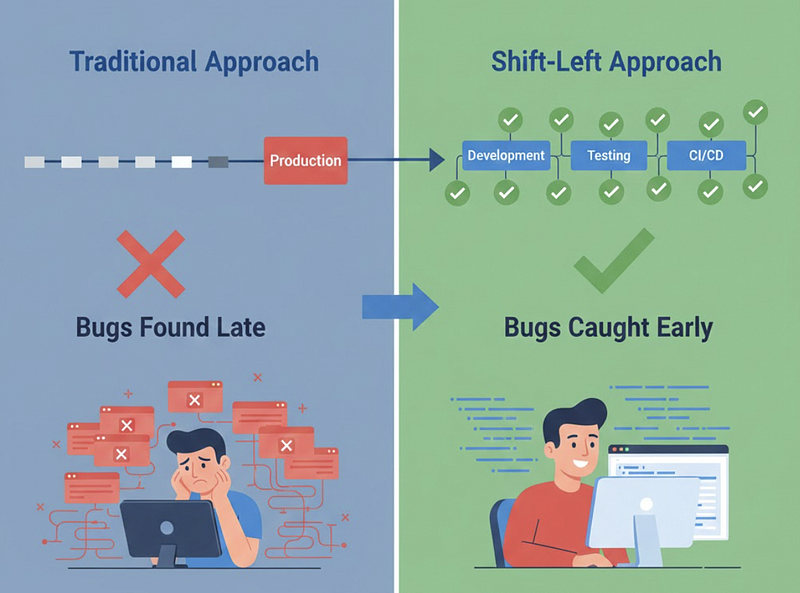
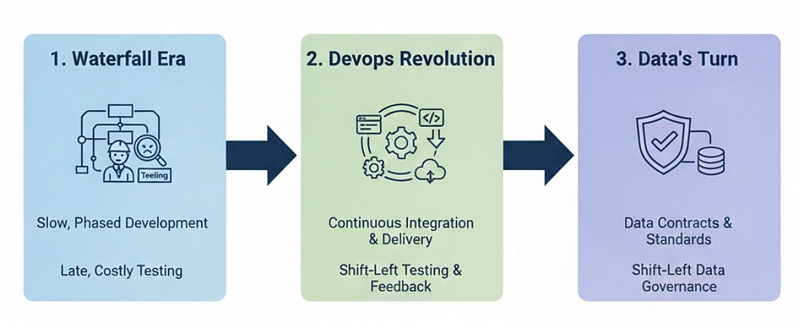
Before DevOps emerged in 2007–2008, software followed a waterfall: developers coded for months, then handed off to operations. Testing happened late. Security reviews happened later. When problems were discovered, fixing them meant rewinding through weeks of work.
DevOps asked a simple question: “What if we caught problems earlier, when they’re cheaper to fix?”
Testing shifted to CI pipelines. Security became automated checks in every commit. Infrastructure became code that developers controlled.
The results? Bugs caught in development cost pennies vs. production. Release cycles accelerated from months to days. Quality improved because the context was fresh.
Now data engineering faces the same inflection point.
Evolution of Development and Data Governance
Read more about the importance of Data Contracts
Data Contracts: The Missing Link in Your Data Engineering Strategy
Traditional Data Governance (Reactive and Broken)
Now data engineering faces the same inflection point that software engineering faced fifteen years ago.
As organisations embraced microservices, cloud platforms, and distributed architectures, data creation became federated across hundreds or thousands of services. Each service produces data — events, logs, transactions — with its own schema and semantics. Data teams downstream try to collect, clean, transform, and harmonise all this data into something usable.
The result? A reactive cost centre that constantly fights fires.
Data engineering teams spend their days debugging inconsistent schemas, resolving data drift when upstream services change, fixing duplicate or contradictory transformations across different teams, and responding to compliance incidents like untracked personally identifiable information (PII) exposure. Much like operations teams before DevOps, data teams have become firefighters instead of builders.
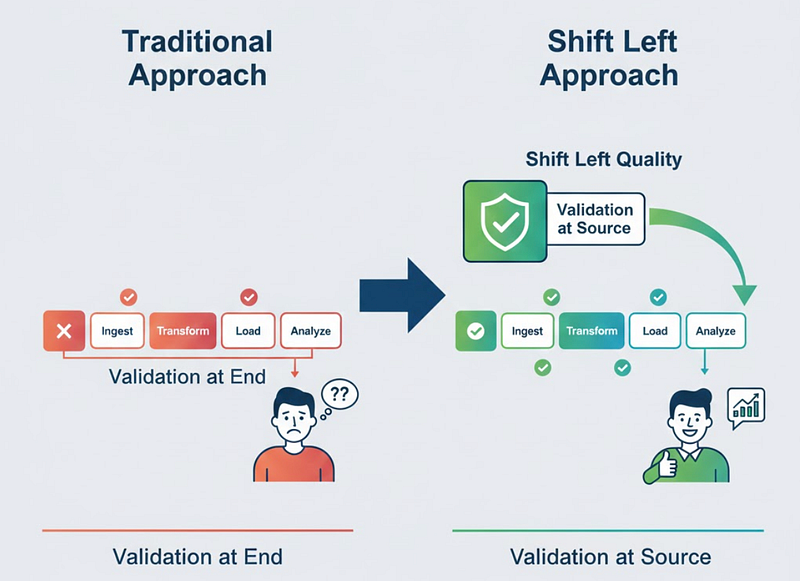
The traditional governance approach — validate data quality after it’s been collected and stored — creates several critical problems:
By the time you detect quality issues, bad data has already propagated. It’s been copied to your data lake, transformed through your pipelines, aggregated into summary tables, and served to stakeholders. Now you’re not fixing one problem; you’re untangling a web of downstream impacts.
Debugging is expensive and time-consuming. When an analyst reports incorrect numbers in a dashboard, tracing the problem back through multiple transformation layers to find the source takes hours. The investigation often takes longer than the fix.
Trust erodes with each incident. Stakeholders learn that data can’t be trusted without verification. Analysts develop elaborate manual checks before trusting any numbers. Decision-makers delay important choices while waiting for “validated” data.
Team morale suffers under constant firefighting. Engineers joined data teams to build innovative solutions, not to spend 70% of their time tracking down why yesterday’s revenue numbers don’t match today’s.

Shift Left Governance
Shifting left in data engineering means moving data quality validation, governance controls, and contract enforcement from downstream validation to upstream.
The philosophical shift is profound. You stop asking “How do we catch bad data before it reaches dashboards?” and start asking “How do we prevent bad data from being created in the first place?”
This isn’t just moving the same validation earlier. It’s fundamentally rethinking who owns data quality and where accountability lives.
The Four Pillars of Shift Left Data Governance
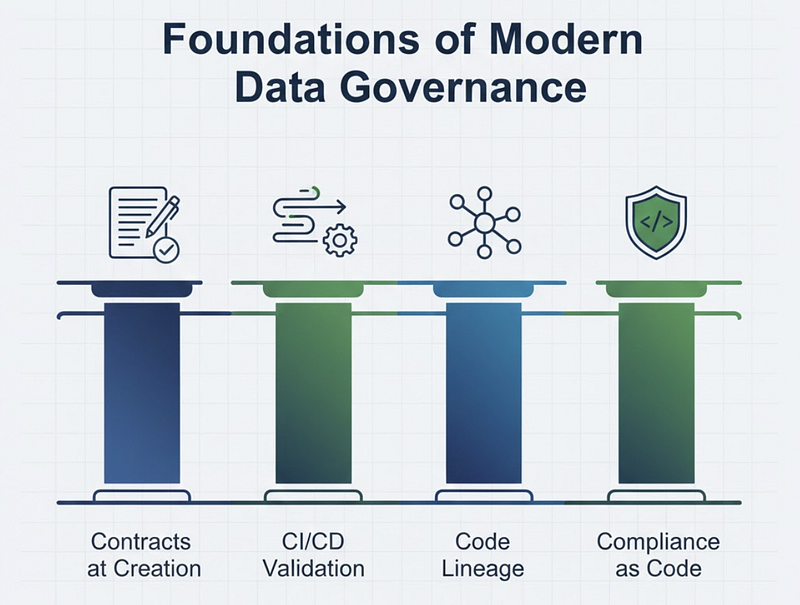
1. Data Contracts at Creation
Define structure, types, quality expectations, and SLAs when data is produced, not after it breaks something downstream. Every data producer commits to a contract that specifies exactly what they’ll deliver.
A backend service that produces customer events doesn’t just emit JSON with whatever fields seem convenient. It commits to a contract: customer_id will always be a string, email will always match a valid email format, created_at will always be an ISO-8601 timestamp, and events will be delivered within 60 seconds of creation.
2. Validation in CI/CD
Build automated schema validation, semantic checks, and freshness monitoring directly into deployment pipelines. Before code ships to production, the contract gets validated. If a developer tries to remove a field that downstream consumers depend on, the build fails. The problem is caught in development, not discovered in production.
3. Code-Level Lineage
Understand how data is created and transformed within source code itself. When data quality issues do occur, lineage tracing starts at the point of creation. You see exactly which code generated the problematic data, who committed that code, and what changed recently.
4. Compliance as Code
Bake policy enforcement into the software development lifecycle. Instead of quarterly compliance audits that find problems months after they occurred, compliance rules are validated with every deployment.
If a service starts collecting PII without proper consent tracking, the contract validation fails. If data with retention policies tries to flow into systems without automatic deletion, it gets blocked. Governance becomes proactive, not reactive.
The Real Business Impact
Organisations that successfully shift governance left see measurable improvements:
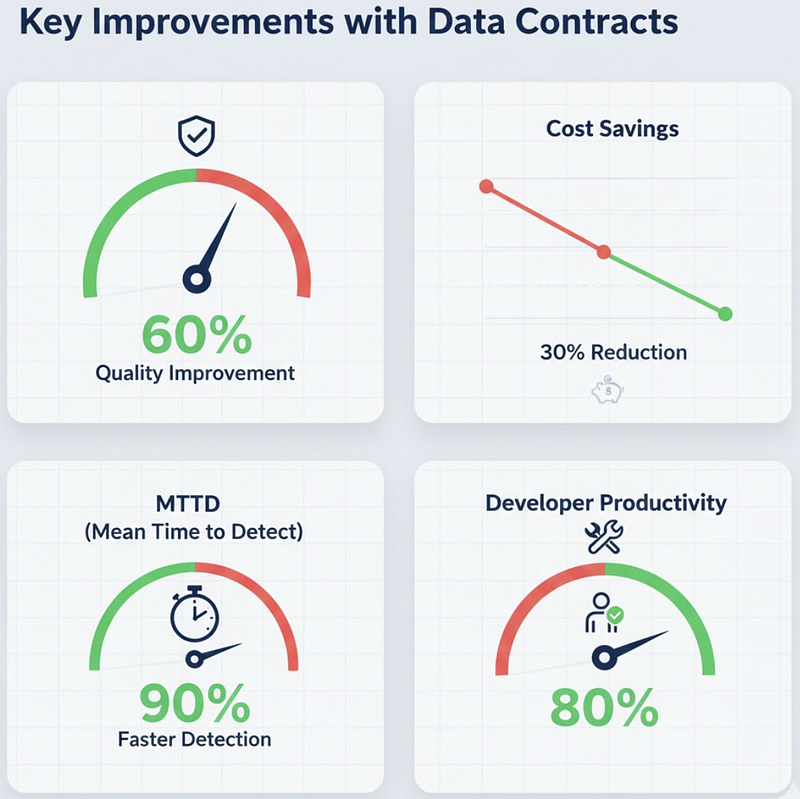
Data quality issues drop by 60%. When validation happens at the source, bad data never enters your systems. The cost of prevention is a fraction of the cost of remediation.
Compute costs decrease by 30%. When you’re not constantly re-processing data to fix quality issues, you consume fewer resources. Clean data flows through pipelines efficiently the first time.
Mean time to detection falls by 90%. Issues are caught immediately at creation, not discovered days later when analysts report discrepancies.
Engineering productivity soars. When your team spends 20% of their time on data quality instead of 70%, they finally have bandwidth to build the features that drive business value.
Perhaps most importantly, trust in data increases dramatically. When stakeholders know that data has been validated at the source with automated contracts, they stop second-guessing every number. Self-service analytics becomes viable because users can confidently consume data without manual verification.
The Future is Proactive
Traditional data governance will always be necessary for historical data, compliance audits, and monitoring. But reactive governance alone can’t keep pace with modern data ecosystems.
Shift left governance doesn’t replace downstream monitoring — it complements it. You maintain data observability tools that watch for anomalies and alert on quality degradation. But instead of those tools being your primary defence, they become your safety net. Most issues are caught upstream at the source. Downstream monitoring catches the edge cases that slip through.
The combination creates defence in depth. Multiple layers of protection, with most validation happening early when problems are cheap to fix.
More importantly, shift left governance changes the nature of data teamwork. Instead of reactive firefighting, teams focus on proactive improvement. Instead of debugging production issues, they’re building better contracts, refining quality rules, and enabling new use cases.
That’s the real transformation: turning data engineering from a cost centre that fixes problems into a value driver that enables innovation.
This article was originally published at https://medium.com/@aradsouza/shift-left-governance-why-you-are-fixing-data-problems-at-the-wrong-time-dbaf7895520d