Understanding where protocol ends and intelligence begins in modern AI agent architectures.
MCP (Model Context Protocol) and agentic skills are not competing concepts — they are complementary layers. MCP is the standardised connectivity layer that defines how an agent reaches external tools and data. Skills are the domain-specific capability modules that define what an agent knows how to do. The most effective agent architectures combine both: skills for intelligent orchestration, MCP for universal tool access. If you are building AI agents and treating these as either/or, you’re leaving architecture on the table.
To make this concrete, we’ll use a single running example throughout: a dbt MCP server and a Databricks MCP server as the connectivity layer, and a custom Pipeline Triage Skill as the intelligence layer that orchestrates across both. By the end, you’ll see exactly where protocol ends and domain logic begins.
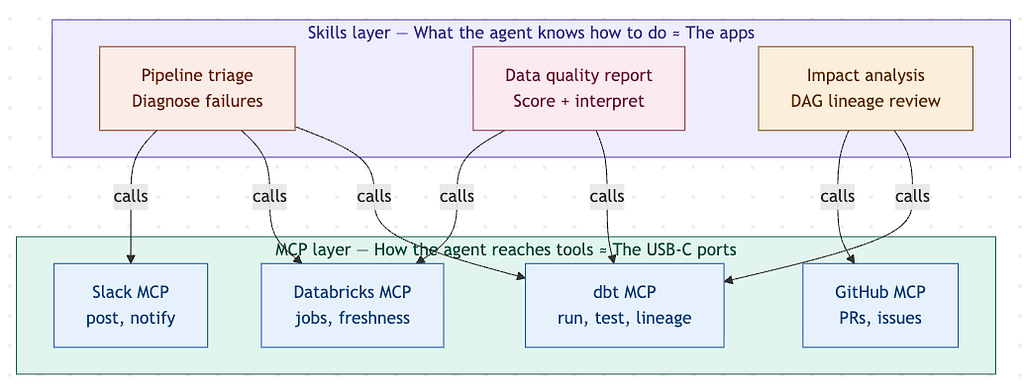
Skills define capability · MCP defines connectivity · Together they form the agent stack
Overview
If you’ve spent any time in the AI agent space recently, you’ve probably encountered two concepts that keep showing up in the same conversations but that few people clearly distinguish: MCP servers and agentic skills. Both relate to how AI agents interact with the outside world, but they operate at fundamentally different levels of the stack.
This article is for data engineers, AI engineers, and platform engineers who are building or evaluating agent architectures and want a clear mental model for where each concept fits. Whether you’re wiring up a dbt project to an LLM or designing a multi-tool agent that triages overnight pipeline failures across Databricks, dbt, and Slack — understanding the MCP and agent skills boundary will sharpen your design decisions.
We’ll start by defining MCP using the dbt MCP server and Databricks MCP server as concrete examples, then introduce the Pipeline Triage Skill to show what skills add on top. From there, we’ll explore how they layer together in a real architecture, compare them side by side, and close with practical guidance for building systems that treat both as first-class citizens.
What Is MCP?
Model Context Protocol (MCP) is Anthropic’s open protocol for connecting AI models to external tools, data sources, and APIs through a standardised client-server interface. Think of it as the USB-C for AI — a universal plug that lets any model talk to any tool without needing custom integration code for each combination.
Before MCP, if you wanted to connect an LLM to your dbt project, you had to write bespoke API glue: authentication handling, request formatting, response parsing, error management. Want to also connect it to Databricks? That meant another round of custom integration code. Multiply that by every tool your agent needs, and you get a combinatorial explosion of integration code — fragile, duplicated, and hard to maintain.
MCP solves this with a clean architectural separation. An MCP server wraps an external tool or data source and exposes its capabilities through a standardised interface. An MCP client lives inside the agent or model runtime, speaks the protocol, and routes tool calls to the appropriate server. The model never needs to know the implementation details of the tool — it just knows what capabilities are available and how to invoke them.
Let’s ground this with our two examples:
The dbt MCP server wraps your dbt project and exposes operations like dbt run, dbt test, listing resources, and parsing DAG lineage — all through the standard MCP interface. Any MCP-compatible agent can discover and invoke these operations without knowing anything about dbt's CLI, manifest files, or project structure.
The Databricks MCP server does the same for your Databricks workspace — exposing capabilities like querying system.lakeflow tables for job run history, checking cluster status, or reading data freshness metadata. Again, the agent doesn't need to know about Databricks REST APIs or authentication flows.
This is a protocol-level concern. Neither MCP server knows or cares why you’re querying dbt logs or Databricks system tables, or what you plan to do with the results. They handle the plumbing: discovery, authentication, invocation, and response formatting. As we’ll see in the architecture section below, this makes MCP the foundation layer that everything else builds on.
But here’s the critical question: if an overnight pipeline fails and your agent can reach both dbt and Databricks via MCP, does it automatically know how to diagnose the failure? That’s where skills come in.
What Are Agentic Skills?
If MCP is the I/O layer, agentic skills are the applications that run on top of it. A skill is a self-contained capability module that encapsulates domain knowledge, prompt templates, reasoning chains, and orchestration logic for a specific task.
Here’s the analogy: MCP is the operating system’s I/O subsystem — it handles file systems, network sockets, and device drivers. Skills are the apps you install on top. The apps depend on the I/O layer to read and write data, but they own the intelligence of what to do with that data.
Let’s make this real with our Pipeline Triage Skill. Imagine your daily customer churn model fails overnight. Without a skill, your agent has raw access to dbt and Databricks via their MCP servers — it could retrieve run logs, query system tables, or list failed tests. But it doesn’t inherently know the workflow of triaging a pipeline failure. It doesn’t know to:
- First check dbt run logs to identify which models and tests failed.
- Then correlate those failures against Databricks system.lakeflow tables to check whether upstream jobs ran late or produced anomalous row counts.
- Then synthesise these signals into a root-cause hypothesis — “the source table arrived 3 hours late, causing a freshness test to trip and cascade downstream.”
- Then format a structured incident summary and post it to the team’s #data-incidents Slack channel with root cause, impacted models, and a recommended re-run sequence.
The Pipeline Triage Skill encapsulates that entire reasoning chain — the sequencing, the cross-tool correlation, the domain judgement about what constitutes a root cause, the knowledge of how your team handles incidents. It’s a workflow, not a single tool call. The skill uses the dbt and Databricks MCP servers under the hood, but the skill owns the intelligence.
The architecture section below formalises this distinction between raw tool access (MCP) and orchestrated domain logic (skills).
Architecture: How MCP and Skills Layer Together
Here’s where the relationship becomes concrete. In a well-designed agent architecture, MCP and skills don’t sit side by side — they stack vertically. Let’s trace our Pipeline Triage example through the full stack:
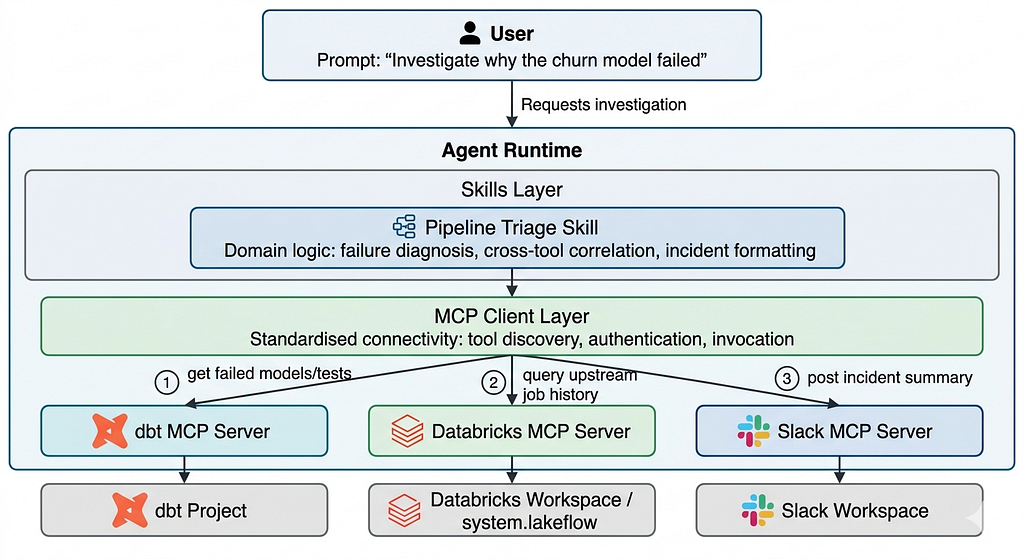
image created by author
What you are seeing: the user asks the agent to investigate a pipeline failure. The agent delegates to the Pipeline Triage Skill, which orchestrates a multi-step diagnosis. At each step, the skill calls the MCP client, which routes the request to the appropriate MCP server — dbt for run logs, Databricks for system table queries, Slack for the incident post. Each MCP server executes one stateless API interaction. The skill owns the reasoning across all of them.
The key takeaway: skills consume MCP — not the other way around. The Pipeline Triage Skill makes three MCP calls during its execution, but MCP never invokes the skill. This directionality is what makes the architecture clean: MCP handles the horizontal breadth of tool connectivity (how many tools can I reach?), while skills handle the vertical depth of task-specific intelligence (what do I do once I get there?).
Notice something important: the dbt MCP server and Databricks MCP server know nothing about each other. Neither knows that another workflow step called the other. Only the Pipeline Triage Skill holds the full picture — it orchestrates the individual MCP calls and chains them into a coherent diagnosis. The comparison table in the next section formalises this layering.
MCP vs Skills: Side-by-Side Comparison
To crystallise the distinction, here’s how MCP and skills compare across the dimensions that matter most when you’re making architecture decisions. We’ll use our running example to ground each row:
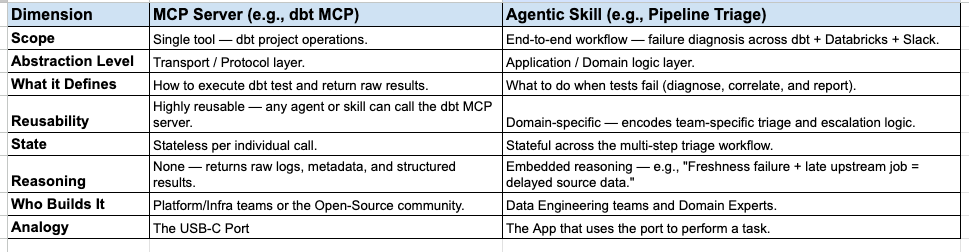
Notice the pattern: every dimension maps to the same fundamental split between connectivity and capability. The dbt MCP server answers “can my agent reach dbt?” The Pipeline Triage Skill answers “does my agent know what to do when a dbt run fails?”
This comparison also highlights where teams sometimes get confused — the overlap section below digs into that.
Where They Overlap — And Where They Don’t
The confusion between MCP and skills makes sense because skills use MCP servers under the hood, which hides the boundary from the outside. When a user says “check why the churn model failed last night”, it looks like a single operation. But architecturally, two layers do the work: the Pipeline Triage Skill decides which logs to pull and how to interpret failure patterns, while the dbt MCP server executes the actual API call to retrieve run results.
The overlap zone is where a skill wraps a single MCP server call with minimal additional logic. Imagine a simple skill that takes a natural-language question like “which dbt models failed today?”, forwards it to the dbt MCP server, and returns the raw result. That’s thin enough to feel redundant — the agent could call the MCP server directly.
So when do you actually need a skill? The answer lies in our Pipeline Triage example.
Skills diverge from MCP when the task requires multi-step reasoning, cross-tool orchestration, or domain-specific judgement. The dbt MCP server can execute dbt test and return logs — but it has no idea what those failures mean. It doesn't know that a freshness test failure on stg_customer_events should trigger a check against Databricks system.lakeflow tables to see whether the upstream ingestion job ran late. It doesn't know that your team classifies this as a Severity 3 incident. It doesn't know to post to #data-incidents rather than #data-general. The skill — not the MCP server — owns all of that orchestration and domain judgement.
The practical rule of thumb, which connects back to the architecture diagram above: if it’s a single tool call, MCP alone may suffice. If it involves judgement, sequencing, or synthesis across tools, you want a skill.
So What?
Now that the MCP-skills mental model is clear, here’s what to do with it:
1. Design your agent architecture in layers. Treat MCP as your connectivity tier and skills as your application tier. Don’t embed triage logic in your dbt MCP server, and don’t hardcode Databricks API calls inside your Pipeline Triage Skill. Clean separation lets you swap tools without rewriting workflows — replace Databricks with Snowflake, and only the MCP server changes; the skill’s reasoning logic stays intact.
2. Start with MCP, add skills as complexity grows. For simple, single-tool interactions — “run dbt test and show me the results" — connecting the dbt MCP server directly to your agent is perfectly fine. Introduce a skill layer when you find yourself writing multi-step prompts, cross-tool orchestration, or conditional logic that the model shouldn't have to figure out from scratch every time.
3. Invest in your MCP server catalogue. The value of skills multiplies with the breadth of your MCP connectivity. Our Pipeline Triage Skill is powerful because it can orchestrate across dbt, Databricks, and Slack. Add a GitHub MCP server, and the same skill could auto-create an issue for the on-call engineer. Treat your MCP server catalogue like an API gateway — the more standardised endpoints you expose, the more sophisticated the skills you can build on top.
4. Think complementary, not competitive. As the agent ecosystem matures, the teams that treat MCP and skills as complementary layers — not as an either/or choice — will build the most robust and maintainable AI systems. MCP gives you the universal reach. Skills give you the domain intelligence. Together, they form the foundation of production-grade agentic architecture.
Found this useful? Follow me on Medium (aradsouza) or LinkedIn https://www.linkedin.com/in/alwynanildsouza/
for more practitioner-voice content on dbt, data mesh, and the modern data stack.
References
[1] Anthropic — Introducing the Model Context Protocol — https://www.anthropic.com/news/model-context-protocol
[2] Anthropic — MCP Servers (GitHub Repository) — https://github.com/modelcontextprotocol/servers
[3] Chip Huyen — AI Engineering: Building Applications with Foundation Models — O’Reilly Media, 2025
[4] dbt Labs — dbt MCP Server — https://github.com/dbt-labs/dbt-mcp
MCP vs Agentic Skills — What’s the Difference, and How Do They Work Together? was originally published in Towards Data Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
This article was originally published at https://medium.com/towards-data-engineering/mcp-vs-agentic-skills-whats-the-difference-and-how-do-they-work-together-0ddaea01f73c?source=rss-670f6306e3c0------2