I treat agile story skills like software. That means I test them, score them, and grade them — using promptfoo — before users hit a regression.
Here is why that matters. A skill can look solid in a demo, then quietly drift after a model upgrade, prompt edit, or when a new edge case sneaks in. One day it produces crisp acceptance criteria. The next day it forgets a required section, writes vague success criteria, or falls back to “as a user” even though the repository explicitly forbids that pattern. The goal is not proving prompts are perfect. The goal is catching regressions before users rely on broken output.
This article uses one skill as the example: agile-story-writer.
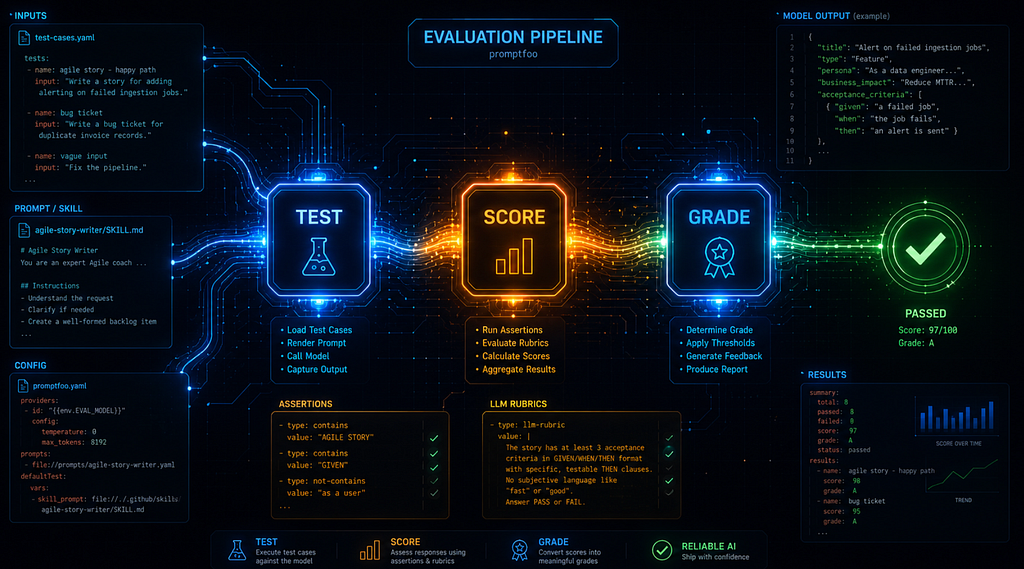
Image created using chatgpt
The Skill: Agile Story Writer
agile-story-writer turns a product or engineering request into a delivery-ready agile story. The skill should reliably produce:
- A deterministic box format
- A specific persona – never the generic “as a user”
- A clear story title starting with an action verb
- Acceptance criteria in GIVEN / WHEN / THEN format
- Scope In and Scope Out sections
- Definition of Ready
- Definition of Done
- Measurable non-functional requirements
That sounds straightforward, but it is exactly where prompt drift hides. A model can produce something that looks like a story while still being vague, hard to test, or structurally broken.
What Goes Into an Eval Run
The main eval lives at evals/agile-story-writer.yaml.
The chat prompt wrapper lives at evals/prompts/agile-story-writer.yaml.
The source skill instructions live at .github/skills/agile-story-writer/SKILL.md.
Promptfoo loads the skill instructions, sends test inputs, captures model outputs, and then checks those outputs with assertions. The flow looks like this:
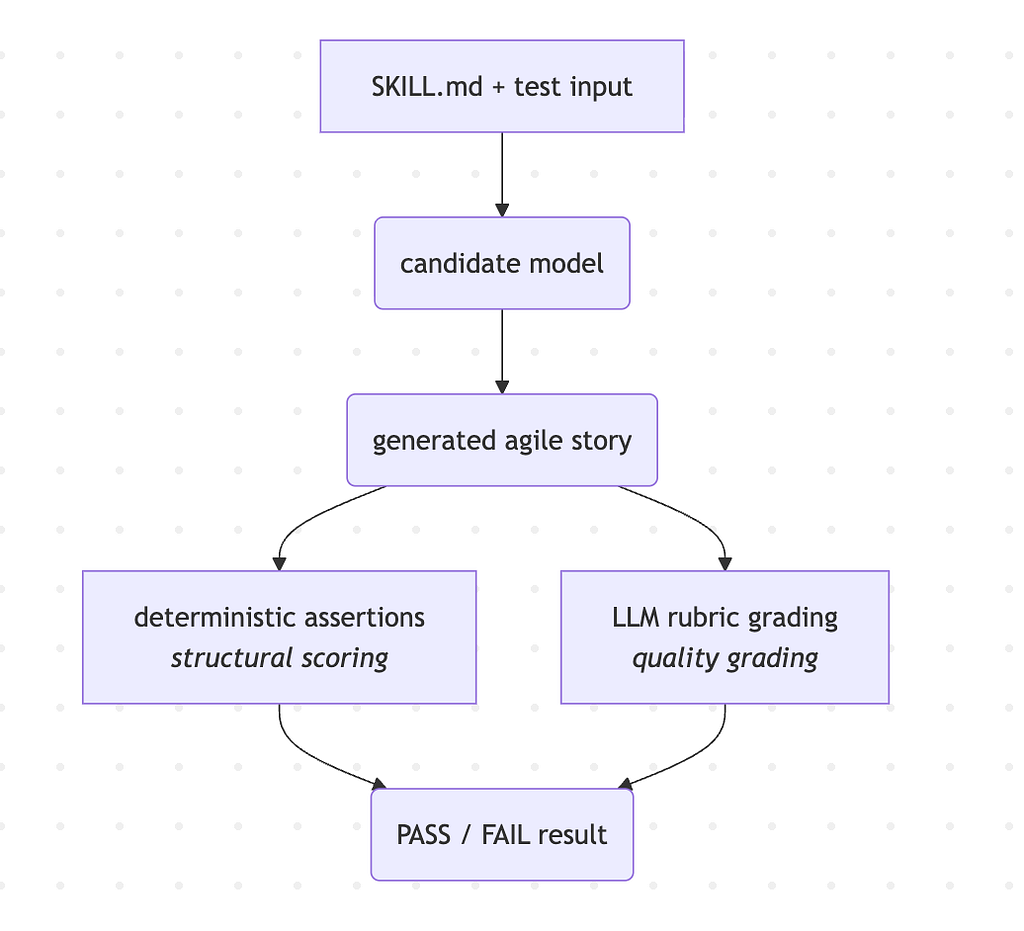
The candidate model is driven by an EVAL_MODEL environment variable, so the same eval runs against Anthropic, OpenAI, Google, OpenRouter, or any other promptfoo-supported provider.
Test, Score, Grade — Why I Separate Them
These three terms are easy to blur. I keep them distinct:
Test — Run a fixed input through the skill.
Score — Use deterministic assertions to mark checks as pass or fail.
Grade — Use an LLM rubric to judge qualitative output quality.
Here is a concrete example:
- Input: Write a story for adding alerts on failed ingestion jobs.
- Test: Promptfoo sends that input to agile-story-writer.
- Score: Promptfoo checks that required sections exist and banned phrases do not appear.
- Grade: An LLM rubric checks whether the title, acceptance criteria, points estimate, and NFRs are actually good.
That combination gives more signal than manual review alone.
Deterministic Assertions: The Cheap, Reliable Layer
Promptfoo scoring starts with deterministic assertions — exact structural checks using contains and not-contains rules.
For agile-story-writer, these include:
# Required structure must be present
- type: contains
value: "╔══"
- type: contains
value: "AGILE STORY"
- type: contains
value: "GIVEN"
- type: contains
value: "WHEN"
- type: contains
value: "THEN"
- type: contains
value: "Scope - IN"
- type: contains
value: "Scope - OUT"
- type: contains
value: "DEFINITION OF READY"
- type: contains
value: "DEFINITION OF DONE"
# Forbidden anti-patterns must not appear
- type: not-contains
value: "as a user"
These assertions are cheap and fast. If the model drops the required output shape, the test fails immediately without needing a grader model call. This gives structural scoring — I can tell whether the output still follows the expected story template before spending tokens on quality evaluation.
LLM Rubrics: Catching Quality Drift, Not Just Structure
Structure is necessary, but structure is not enough. A weak story can still contain GIVEN, WHEN, and THEN while being vague or untestable. That is why I layer in llm-rubric assertions.
For agile-story-writer, rubric checks ask a grader model questions like:
- Does the title start with an action verb such as Add, Build, Create, Fix, Migrate, or Expose?
- Does the story have at least three acceptance criteria?
- Is each acceptance criterion written in GIVEN / WHEN / THEN format?
- Does each THEN clause describe something specific and testable?
- Does the points field use a Fibonacci estimate with a rationale?
- Does the NFR table include specific, measurable performance, security, and observability entries?
The grader is not checking whether labels exist. It is checking whether output quality meets the bar. That is the grading layer — and it is where prompt drift that survives structural checks finally gets caught.
How CI Uses Promptfoo — Without Fake Passes
The CI workflow lives at .github/workflows/automated-evaluation.yml. It runs on pull requests that touch skill, agent, eval, package, or script files.
Model selection works through repository secrets in priority order:
- EVAL_MODEL when explicitly set
- Anthropic default when ANTHROPIC_API_KEY exists
- OpenAI default when OPENAI_API_KEY exists
- Google default when GOOGLE_API_KEY exists
- OpenRouter default when OPENROUTER_API_KEY exists
If no provider key exists, CI skips live evals with a visible warning. It does not silently pass with mock output. That distinction matters — a skipped eval should be visible. A fake pass is worse than no eval at all.
Reading Failures: Where to Look First
Not every failure means the skill prompt is wrong. Reading the actual output is always the right first step.

How This Pattern Extends to Other Skills
agile-story-writer is one example. The same structure applies across the full suite:

Each suite has different assertions and rubrics, but the same core pattern: fixed input → model output → structural score → quality grade → pass/fail.
What I Would Add Next
The current setup catches structural and quality regressions reliably. What it does not yet do is track trends — whether quality scores are slowly degrading across model versions rather than failing hard on a single run. The next evolution I am considering is storing rubric scores as numeric values over time so I can spot slow drift before it becomes a failure.
The other gap is cross-provider parity testing: running the same suite against two models simultaneously and flagging where rubric scores diverge significantly. That would make model upgrade decisions much more data-driven.
The pattern is solid. The tooling is mature enough to build on.
Repository Links
- agile-story-skills repository
- Agile Story Writer skill
- Agile Story Writer promptfoo eval
- Agile Story Writer prompt wrapper
- Promptfoo eval workflow
- Eval cost report script
This article was originally published at https://aradsouza.medium.com/how-i-use-promptfoo-to-test-and-grade-an-agile-ai-skill-20e3e66cb3c4?source=rss-670f6306e3c0------2