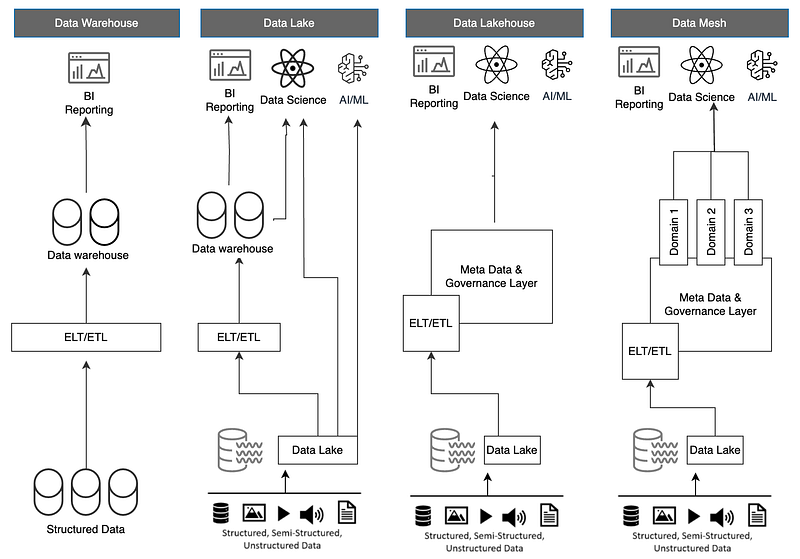
Data Warehouse Architecture (1980s)
The journey of data architecture began in the late 1980s with the advent of data warehouses. This period was characterised by on-premises infrastructure and relational databases that managed structured data within rigid hierarchies. The primary aim was to consolidate data from various operational systems into a centralised repository for reporting and analysis.
Benefits:
- Centralised Data Management: Data warehouses functioned as the central repository where data was extracted, transformed, and loaded (ETL) into predefined schemas.
- Schema-Driven Organisation: Data was structured into star or snowflake schemas, facilitating SQL queries for business intelligence (BI) purposes.
- Batch-Oriented Processing: Data movement was predominantly batch-oriented, with periodic updates rather than real-time processing.
Challenges:
- High Complexity: Over time, the architecture became overly complex, with numerous ETL jobs and reports managed only by specialised teams.
- Inflexibility: The rigid schema design hindered adaptation to the growing volume and variety of data, especially unstructured data.
- Slow Iteration: The focus on upfront modeling and ETL processes resulted in slower data access and limited scalability.
Data Lake Architecture (2010s)
The limitations of data warehouse architecture led to the emergence of the data lake in the 2010s. This generation was driven by the need to handle the explosion of data generated by the internet, social media, and IoT devices.
Benefits:
- Scalability: Data lakes were designed to store massive amounts of raw, unstructured data, enabling organisations to capture data in its original form.
- Flexible Processing Approach: Unlike data warehouses, data lakes followed an extract, load, transform (ELT) approach, where data was loaded into the lake before being transformed.
- Zone-Based Storage: Data lakes introduced zones, ranging from raw data to fully cleansed and processed data.
Challenges:
- Data Swamps: Without proper governance, data lakes quickly deteriorate into data swamps, where data became unmanageable and untrustworthy.
- Complex Pipelines: The architecture required complex processing pipelines, often managed by highly specialised data engineers.
- Poor Data Quality: The lack of upfront modeling made it difficult to ensure data quality, leading to inconsistencies and reliability issues.
Cloud Data Lake Architecture (2020s)
The advent of cloud computing in the 2020s brought about the third generation of data architecture: the cloud data lake or “Lakehouse.” This era saw the convergence of data lakes and data warehouses.
Benefits:
- Cloud-Native Design: Leveraging cloud services, the architecture offered scalability, elasticity, and cost-efficiency, enabling organisations to handle vast amounts of data with ease.
- Real-Time Data Processing: The architecture supported both batch and stream processing, enabling real-time data availability and decision-making.
- Unified Data Platform: The Lakehouse architecture integrated the best features of data lakes and warehouses, allowing for structured, unstructured, and semi-structured data to coexist in a single platform.
Challenges:
- Complex Management: Despite improvements, the architecture still required specialised teams to manage and maintain data quality.
- Centralised Nature: The architecture’s centralised design limited its ability to scale across diverse business domains.
- Delayed Access to Insights: Data consumers often had to wait for extended periods to access insights, limiting the architecture’s effectiveness in fast-paced environments.
Data Mesh Architecture (Future)
Looking to the future, the fourth generation of data architecture — Data Mesh — aims to address the challenges of previous generations by decentralising data management and ownership.
Benefits:
- Domain-Oriented Ownership: Data Mesh decentralises data ownership, assigning responsibility for data to individual business domains. Each domain manages its own data products, including storage, processing, and governance.
- Data as a Product: In Data Mesh, data is treated as a product, with each domain delivering data products that are easily discoverable, accessible, and reusable by other domains.
- Self-Service Infrastructure: The architecture provides a self-service infrastructure that allows teams to manage their data independently, without relying on centralised data teams.
- Federated Governance: Data governance is embedded within each domain, ensuring data quality, privacy, and security across the organisation.
Advantages:
- Scalability: Data Mesh scales horizontally across business domains, making it easier to manage large volumes of data in diverse environments.
- Agility: The architecture supports rapid iteration and innovation, allowing teams to quickly adapt to changing business needs.
- Empowerment: By decentralising data ownership, Data Mesh empowers teams to take full control of their data, leading to faster insights and better decision-making.
References
This article was originally published at https://medium.com/@aradsouza/evolution-of-data-architecture-a-comparative-analysis-04a6d74e11a4