dbt fusion : Under the Hood—The Technical Architecture
More Than Just “Faster”
The dbt Fusion Engine represents a fundamental architectural evolution from the legacy Python-based dbt Core runtime, designed to deliver high performance, developer productivity, and advanced governance.
When developers first hear “30x faster parsing,” they often think it’s just about optimised code. But fusion’s speed is a byproduct of something more profound: Fusion truly understands your SQL code and has a full view of what it means and how it propagates across your entire data lineage.
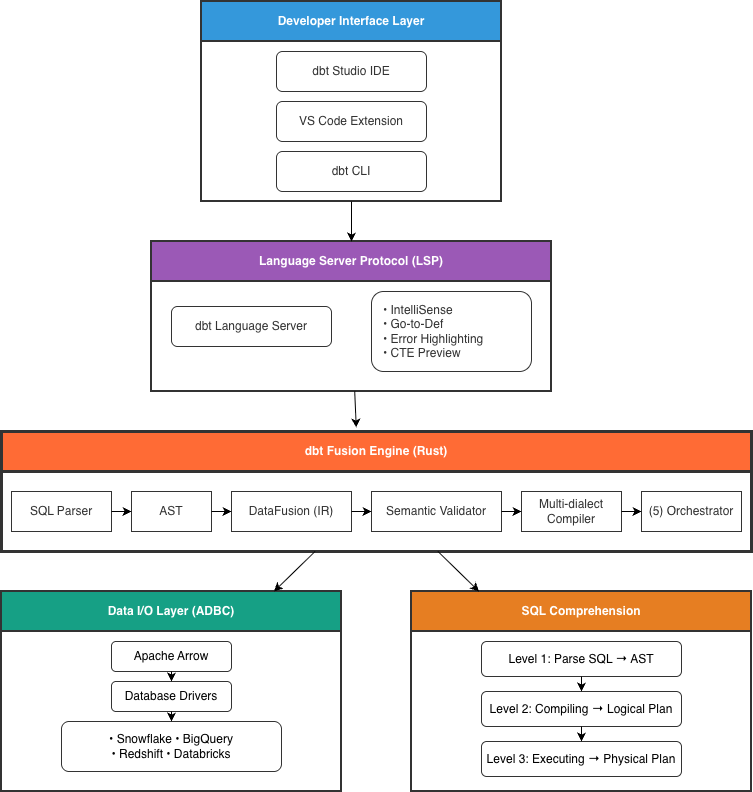
Diagram created by author using mermaid
Foundation: The Rust Runtime (dbt-fusion)
The primary architectural shift is the complete rewrite of the core parsing and compilation logic in Rust. This decision addresses the performance and concurrency limitations of the Python runtime.
- Performance: Rust compiles to a single, native binary with zero runtime overhead, enabling the 30x faster project parsing widely cited in dbt Labs documentation. This is crucial for maintaining developer flow in large-scale projects.
- Correctness and Safety: Rust’s memory safety and concurrency primitives enhance the reliability and stability of the engine, particularly in long-running IDE sessions.
- Deployment: The engine is distributed as a standalone binary, requiring no external Python dependencies beyond the necessary database drivers
Compilation and Semantic Validation: SQL Comprehension
The Fusion Engine moves from treating SQL as a text template (Jinja) to a language that can be semantically understood.
The engine performs Level 2 SQL Comprehension using a Logical Plan (Intermediate Representation) built via Apache DataFusion. This allows for “Shift Left” validation:
- Zero-Warehouse Validation: Unlike dbt Core, which must send a query to the warehouse to see if it fails, Fusion builds a local semantic graph. It knows the schema of your upstream models from previous runs (via the manifest) and the AST of your current model.
- Column-Level Tracking: If you delete a column in stg_customers, the Semantic Validator immediately flags every downstream model referencing that column with a "Column Not Found" error in the IDE—before you ever hit "Run."
- Type Safety: It validates that you aren’t trying to perform a mathematical operation on a string, catching type mismatches instantly.
Developer Interface: Language Server Protocol (LSP)
The LSP is the standard decoupling mechanism that translates the Fusion Engine’s complex contextual understanding into real-time interactive features within IDEs (dbt Studio, VS Code Extension).
- Real-time Intelligence: The engine hosts a dbt Language Server that communicates via the LSP to provide features like IntelliSense, autocompletion for models and columns, Go-to-defintion, and inline error highlighting.
- Incremental Compilation: The LSP enables the engine to track and recompile only the delta of changes, ensuring a near-instantaneous feedback loop for the developer.
Data I/O: Arrow Database Connectivity (ADBC)
For high-performance interaction with the data warehouse, Fusion leverages the Apache Arrow ecosystem.
- Columnar Data Transfer: ADBC drivers facilitate fast, memory-efficient data transfer using the Arrow columnar format, optimizing data movement during tasks like query previews and data quality checks.
- Unified Interface: ADBC provides a standardized interface for adapters, reducing complexity and increasing speed compared to traditional row-based ODBC/JDBC connectors.
Execution Logic: State-Aware Orchestration
In a dbt Cloud context, the Fusion Engine informs dbt Orchestrator components.
- Model State Tracking: By tracking the production manifest and comparing it against source data freshness and code changes, the engine enables state-aware runs.
- Cost Optimization: This orchestration logic allows jobs to automatically determine the minimal set of models that need to be rebuilt, leading to significant warehouse compute cost reductions.
Fusion isn’t just optimized Python — it’s a fundamental architectural reimagining built on modern languages (Rust), industry standards (LSP, ADBC), and advanced SQL compilation. This foundation enables experiences impossible in dbt Core.
Found this useful? Follow me on Medium (aradsouza) or LinkedIn https://www.linkedin.com/in/alwynanildsouza/
for more practitioner-voice content on dbt, data mesh, and the modern data stack.
References
- GitHub - dbt-labs/dbt-fusion: The next-generation engine for dbt
- About the dbt VS Code extension | dbt Developer Hub
dbt fusion — Under the Hood — The Technical Architecture was originally published in Towards Data Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
This article was originally published at https://medium.com/towards-data-engineering/dbt-fusion-under-the-hood-the-technical-architecture-ca28d7f5ba0d?source=rss-670f6306e3c0------2