In today’s>The Growing Challenge of PII Management
As businesses migrate to modern data platforms like Databricks, they often discover that PII is scattered across numerous datasets, tables, and columns without proper governance. This creates significant risks:
- Regulatory compliance violations under GDPR, CCPA, and other privacy regulations
- Data breach vulnerabilities from unprotected sensitive information
- Operational inefficiencies from manual PII identification processes
- Downstream data quality issues when PII handling is inconsistent
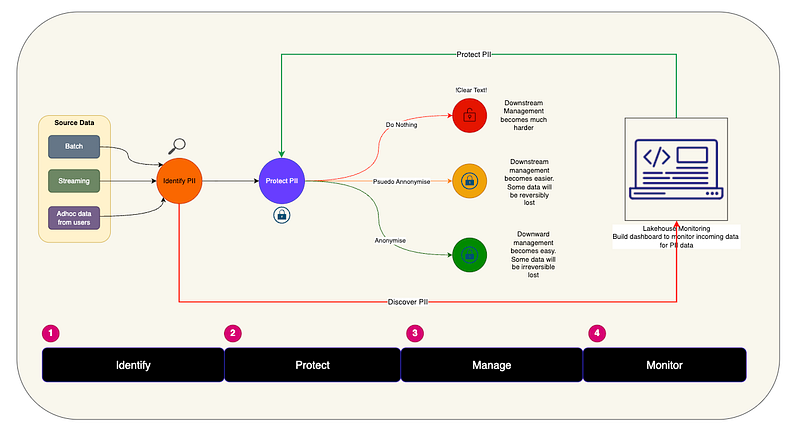
The solution requires a systematic, four-phase approach: Identify, Protect, Manage, and Monitor.
Phase 1: Identify — Discovering PII Across Your Data Landscape
The foundation of effective PII management begins with comprehensive identification. This phase involves conducting thorough audits and utilizing automated tools to detect PII data across your entire Databricks catalog.
What Constitutes PII?
Understanding what qualifies as PII is crucial for effective identification. The comprehensive list includes:
Direct Identifiers:
- Names and personal details
- Date of birth
- Postal or billing addresses
- Email addresses
- Phone numbers and mobile identifiers (MSISDN)
Technical Identifiers:
- IMSI (SIM numbers) and IMEI (device numbers)
- Identification documents (driver’s license, Medicare, passport numbers)
- Login credentials and system IDs
Financial and Employment Data:
- Payment card information
- Tax file numbers
- Employee records and salary information
Behavioral and Communication Data:
- Location data and browsing patterns
- Communication content (SMS, MMS, voice recordings)
- Internet usage sessions and patterns
Sensitive Personal Information:
- Racial, ethnic, or religious information
- Political opinions and sexual orientation
- Criminal records and health data
- Biometric information (fingerprints, facial features, voice patterns)
Automated PII Detection with Regex Rules
Manual PII identification is time-consuming and error-prone. The solution lies in building automated PII scanners using regex patterns tailored to your data formats. Here are some key regex rules for Australian data:
# Australian phone number (international format)
phone_number_rule = {
"name": "phone_number",
"description": "Australian phone number",
"definition": r"^61\d{9}$",
"match_example": ["61123456789"],
"nomatch_example": ["123456789"],
}
# Australian mobile number (local format)
mobile_number_rule = {
"name": "mobile_number",
"description": "Australian mobile number starting with 04",
"definition": r"^04\d{8}$",
"match_example": ["0478111628"],
"nomatch_example": ["1478111628"],
}
# Australian postcode
postcode_rule = {
"name": "postcode",
"description": "Australian postcode",
"definition": r"^\d{4}$",
"match_example": ["2000", "3000"],
"nomatch_example": ["123", "12345"],
}
# IMEI (International Mobile Equipment Identity)
imei_rule = {
"name": "imei",
"description": "International Mobile Equipment Identity",
"definition": r"^\d{15}$",
"match_example": ["490154203237518"],
"nomatch_example": ["49015420323751"],
}
# Australian passport number
passport_number_rule = {
"name": "passport_number",
"description": "Australian passport number",
"definition": r"^[A-Z]{2}\d{7}$",
"match_example": ["AB1234567"],
"nomatch_example": ["ABC1234567"],
}
These regex patterns form the foundation of an automated scanner that can traverse your entire Databricks catalog, examining schemas, tables, and columns to identify potential PII data.
Phase 2: Protect — Implementing Access Controls and Tagging
Once PII is identified, the next critical step is protection through systematic tagging and access control implementation.
PII Tagging Strategy
Effective tagging serves multiple purposes:
- Categorizes data for easier management and compliance reporting
- Enables automated policy enforcement across your data platform
- Facilitates audit trails for regulatory compliance
- Supports data lineage tracking for impact analysis
Implement a consistent tagging taxonomy that includes:
- PII sensitivity levels (High, Medium, Low)
- Data categories (Financial, Health, Contact, etc.)
- Regulatory classifications (GDPR, CCPA applicable)
- Retention requirements and data lifecycle stages
User Roles and Access Controls
Establishing clear access controls ensures that only authorized personnel can view or handle sensitive information. This involves:
Role-Based Access Control (RBAC):
- Data analysts with masked PII access only
- Data scientists with pseudonymized data access
- Compliance officers with full PII visibility
- System administrators with emergency access protocols
Principle of Least Privilege:
- Grant minimum necessary access for job functions
- Implement time-bound access for temporary requirements
- Regular access reviews and recertification processes
- Automated access provisioning and deprovisioning
Phase 3: Manage — Data Protection Strategies
The management phase focuses on implementing appropriate protection measures for different use cases and risk levels.
The Protection Spectrum
Organizations have several options for managing PII, each with distinct trade-offs:
1. Do Nothing (Clear Text)
Approach: Leave PII in its original form Use Cases: Highly controlled environments with strict access controls Risks: Maximum exposure risk; requires robust downstream protection Consideration: This approach places the burden of PII management on downstream data models and applications
2. Pseudo-Anonymization
Approach: Replace identifiable information with key-coded values Benefits:
- Maintains data utility for analysis
- Preserves referential integrity across datasets
- Allows for controlled re-identification when necessary
- Reduces risk while enabling business insights
Example Implementation:
- Replace phone number “0478111628” with coded value “PHONE_12847”
- Maintain lookup tables in secure environments
- Enable analytics while protecting individual identity
3. Full Anonymization
Approach: Completely remove identifiable information Benefits:
- Eliminates re-identification risk
- Simplifies compliance requirements
- Enables unrestricted data sharing for research
- Reduces storage and processing overhead
Trade-offs:
- Some data utility may be lost
- Certain types of analysis become impossible
- Irreversible data transformation
Implementation Strategies
The choice between these approaches depends on:
- Regulatory requirements in your jurisdiction
- Business use case requirements for data analysis
- Risk tolerance of your organization
- Technical capabilities of your data platform
Many organizations implement a hybrid approach, using different protection levels based on data sensitivity and usage patterns.
Phase 4: Monitor — Continuous Oversight and Compliance
Effective PII management requires ongoing monitoring and visibility into your data protection posture.
Dashboard-Driven Monitoring
Create comprehensive dashboards that provide:
PII Inventory Tracking:
- Total volume of identified PII across catalogs
- Distribution of PII types and sensitivity levels
- Trends in PII discovery and classification
Protection Status Monitoring:
- Percentage of PII with appropriate protection measures
- Untagged or unprotected PII identification
- Policy compliance metrics and exception reporting
Access Pattern Analysis:
- Who is accessing PII data and when
- Unusual access patterns that may indicate security issues
- Audit trail completeness and data lineage tracking
Compliance Reporting:
- Ready-made reports for regulatory requirements
- Data retention compliance tracking
- Breach notification preparation and response metrics
Automated Alerting and Remediation
Implement automated systems that:
- Alert on newly discovered unprotected PII
- Flag policy violations or unusual access patterns
- Trigger automated protection workflows where appropriate
- Generate compliance reports on scheduled intervals
This article was originally published at https://medium.com/@aradsouza/databricks-pii-identification-protection-and-management-e75f2ca66f46